Дааа 


Ось системы это как Ось зла?
1 лайк
Дык поэтому меня вариант с плагином не заинтересовал, мне тоже дискомфортно если слушать можно только в свитпоте. В моем варианте слушать можно из любой точки комнаты (квартира-студио точнее), по оси нормальная сцена, при смещении в сторону - съезжает равномерно не теряя объема, но инструменты несколько меняют положение, без дискомфорта.
Это аудиотрип
Никакой сцены не услышал, звук как из колодца.
Я, конечно, не 0,8, а 0,3 поставил. Сейчас поправлю.
В наушниках тоже услышал больше реверба
Оно в наушниках корректно не будет работать, только как описано для расположения АС, ну и немного их надо будет вокруг оси покрутить для фокусировки, ибо плагин не знает точно внеосевые для АС. При любом отклонении от свитпота (или некорректной расстановке) будут аудиоглюки.
Не, я ж не серьезно слушал — так интересно было что изменилось. Серьезно попробую ближе к выходным.
У B&O есть хороший пример трека с описанием локализации КИЗов — Jennifer Warnes “Bird on a Wire” (в Тидале, например, он есть), рекомендую как одну из удобных тестовых записей для проверки сцены. В идеале там такая панорама:
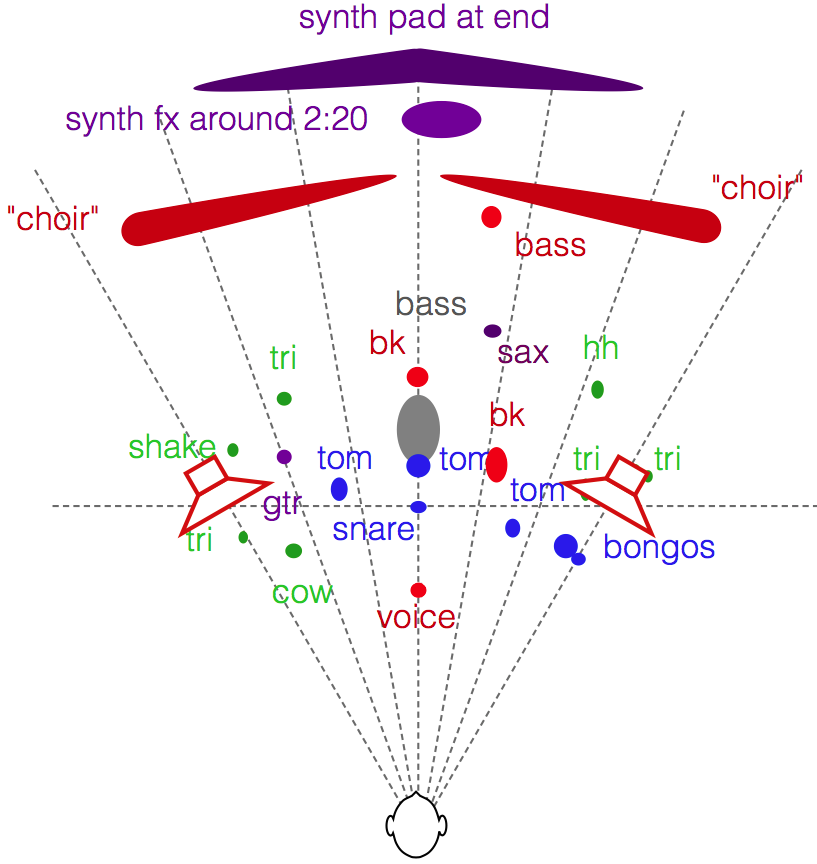
А не в идеале чаще всего примерно такая:
Короче, пока лучший вариант по локализации что я слышал для этого трека (а я его уже долгое время пользую в качестве тестового) - именно с амбиофоник эффектом, очень близко к нарисованному, притом что комната у меня мягко говоря печальная щас для стерео.
До этого лучший результат был у товарищей на студии — но там локализация то четкая, но не материальная, КИЗы пальцем показать не сложно, но “поверить” в их существование сложно. Для работы по панарамированию подходит, но аудиофильских (глючных)) радостей не доставляет.
Забыл, кстати, послушать этот трек на B&O в Варшаве 
Выложите оригиналы плс, чтоб не искать.
1 лайк
Да в принципе и в наушниках должно работать. Схема примерно та же, механизм понятен, решения известны.
А в наушниках и так перекреста каналов “по воздуху” нет, там это зачем? Ну а с записями после плагина будет просто изврат, там он на определенный стерео-треугольник рассчитывает че подмешивать в сигнал.
Ну вот я вроде про механизмы и решения тоже понимал и знал, но только дошли руки попробовать. Если эффект получится настроить - эффектно очень. Приживется ли на постоянку посмотрим, пока слушаю, нравится.
Чтобы немного “вынуть звук из головы”. Там не только сигнал подмешивается - наверняка и фазовые и частотные и пространственные обработки. Я и попросил оригиналы чтобы напрямую сравнить. В принципе тема достаточно древняя и отработаная - моё мнение что именно для наушников (не именно это, а подобное) работает наиболее интересно. Правда быстро надоедает
У меня не было мнения на эту тему Наушники мне вообще не особо интересны, плагины для наушников разные пробовал - не цепляло ничего.
А вот в стерео усилить 3d картинку - мне лично нравится. Если описать ощущения… То очень условно похоже на прослушивание бинауральных записей в наушниках, но только звук не в голове, а обычная для стерео сцена, широкая, глубокая. Чем-то еще на многоканал похоже, сложно на пальцах объяснить…
Алгоритм RACE (Recursive Ambiophonic Crosstalk Elimination) работает следующим образом: к левому каналу подмешивается инвертированный правый канал с определенными аттенюацией и задержкой, которая вычисляется исходя из угла раскрыва акустики. В свою очередь, этот сигнал тоже надо скомпенсировать и т.д. (рекурсия). Аналогично для правого канала. При прослушивании обработанной таким образом записи в наушниках кроме эффекта Хааса (смотрите, ревер добавился;) ) ничего интересного не услышите, т.к. она предназначена исключительно для АС. Вообще-то, изначально метод был разработан в целях адаптации бинауральных записей для акустики, ибо каждое ухо в этом случае должно воспринимать только “свой” канал, но практика показала, что классические стерео-записи, сведенные для прослушивания на стерео-паре, довольно эффектно воспринимаются после исключения взаимопроникновения каналов. В реальности источники звука все-таки монофонические. Алан Блюмлайн прекрасно понимал ограничения разработанного им метода воспроизведения, не стоит воспринимать его патент как истину в последней инстанции. Ограничений у амбиофонии тоже немало, начиная с некорректности строго решения задачи crosstalk elimination в области НЧ при малых углах раскрыва, заканчивая необходимостью подстройки под индивидуальную HRTF и отслеживанием микродвижений головы слушателя (уже реализовано в методе BACCH-SP). Устраивать на эту тему холивар совершенно не стоит, все копья сломаны десятилетия назад. Исходники:
Adele - Hello
Nocturne 3
Flight
2 лайка
Это Вы crosstalk elimination с crossfeed перепутали. Для этой цели куда больше подходит Smith Realizer, но лучше поменять наушники.
Послушал Hello в наушниках (DT770@250) и на акустике средного поля (G1032А) в акустически обработанной студии. По сравнению с оригиналом добавлено бешеное количество частотнозависимой реверберации (больше всего на СЧ), есть небольшой делэйчик, произведена частотная коррекция и кроссфид в оба канала. Изменены соотношения вокала и аккомпанемента (не вдавался как, а принципе есть некоторые плагинчики для подобного - но это интересная тема). Практически заново смоделировано пространство реализации звукового поля и его составляющих. С точки зрения слушателя - оригинал звучит гораздо интереснее и “правильнее”. В обработанном треке такое ощущение что начинающий звукооператор дорвался до студийных приборов и накрутил везде всего по самое не балуйся
Вердикт - решение видимо только для систем с матрасом акустическим экраном между ушей. Такую конфигурацию не пробовал, может в ней действительно что-то интересное есть.
И да - эффект Хааса к реверберации ну никаким боком
Это вы попутали - https://en.wikipedia.org/wiki/Crossfeed
Наушики мои (и студийные) меня вполне устраивают, но спасибо за заботу, очень ценный и главное - оригинальный совет
Процитирую ответ [Андрея Смирнова] (http://soundex.ru/index.php?/topic/43976-влияние-комнаты/&page=3#comment-1481805) на аналогичный вопрос:
On 5/31/2016 at 4:37 PM, Сергей Михайлов said:
Вы - звукорежиссер? Вопрос адресовался именно ему.
И кстати, повторяю вопрос Вам, Андрей, причем тут эффект Хааса?
Нет, я не звукорежиссер, но по проектам моего проектного бюро построены десятки студий звукозаписи, телевизионных студийных комплексов и съемочных павильонов. Поэтому я немного (!!!) в курсе звукорежиссерской кухни
Панорамирование и масштабирование звуковой сцены выполняется звукорежиссером в контрольной комнате. При этом очень важны акустические условия в помещении: структура ранних отражений, их интенсивность и время прихода в точку сведения, время реверберации и т.п.
Эффект Хааса широко применяется практике студийного сведения записей. Локализация виртуальных источников на звуковой сцене создается звукорежиссером в том числе с помощью законов психоакустики. Эффект Хааса помогает звукорежиссеру “расположить” КИЗ в нужном месте, манипулируя уровнем звукового сигнала и его задержкой. Таким образом, например, расширяется стереопанорама.
Очевидно, что для обеспечения необходимых условий сведения и мастеринга, звукорежиссер должен слышать каждый звук “отдельно, четко и ясно”. Одним из необходимых условий является низкое значение времени реверберации.
При использовании задержки полезных сигналов эффект Хааса проявляется следующим образом:
Задержка <3 мс - источник не смещается и локализуется по центру сцены, но немного изменяется тембральная окраска.
Задержка 3-10 мс - объект немного смещается в направлении, откуда сигнал приходит раньше.
Задержка 10-35 мс - локализация в точке, откуда сигнал пришёл раньше, даже если уровень во втором мониторе больше (до 10 дБ).
Задержка более 35-50 мс – появляется искусственная реверберация.
Виртуальный источник можно переместить достаточно далеко от монитора, если добавить в сигнал одного из каналов перекрестный сигнал из другого канала с некоторой задержкой и инверсией по фазе.
Рассматриваемые вопросы достаточно глубоко изучались многими известными акустиками, например, инженерами из Philips Research Laboratory в работе “The Influence of Antiphase Crosstalk on the Localization Cues in Stereo Signals”, AES 1983.
Для угла раскрыва АС 16 градусов (мониторы в студии были установлены именно так?) величина задержки составляет 70 мс - никакого противоречия. Ссылка на указанную публикацию.
Повторюсь: при crossfeed отсутствует инвертирование фазы подмешиваемого сигнала, более того - crosstalk elimination выполняет прямо противоположную функцию.[quote=“Dmitry, post:38, topic:3129”]
Наушики мои (и студийные) меня вполне устраивают, но спасибо за заботу, очень ценный и главное - оригинальный совет
[/quote]
Все куда проще - речь о том, что при текущей стоимости Smith Realizer лучше потратить кровные на наушники. Не стоит принимать сказанное на свой счет 
Касательно результатов прослушивания - Hello действительно звучит слишком затянуто и с заметным тональным окрасом. Меня больше устраивает результат обработки акустических записей.
В цитате А. Смирнова описан классический случай эффекта Хааса, только понятие “реверберация” упомянуто неправильно. Описываемый эффект называется flanger, delay, echo - в зависимости от времени задержки. Реверберация - это другой, более комплексный процесс.
И, если что, я немного больше Андрея в курсе “звукорежиссёрской кухни”
Так это вы мне пытались приписать рассказ о кросстоке, хотя я описывал совсем другое
Этот девайс мне при любой стоимости не нужен